Statistical Analysis: Essential Concepts and Techniques
Five Number Summary and Outliers
The five-number summary includes the minimum, first quartile (Q1), second quartile (Q2), third quartile (Q3), and maximum. Outliers are values above Q3 + 1.5xIQR or below Q1 – 1.5xIQR.
Shifting and Scaling Data
Shifting data by adding a constant C:
- Mean and median increase by C.
- Spread remains unchanged.
Scaling data by multiplying by a constant C:
- Mean, median, and standard deviation (SD) are multiplied by C.
- Variance is multiplied by C2.
The 68-95-99.7 Rule
This rule states the approximate percentage of observations that fall within 1, 2, and 3 standard deviations of the mean in a normal distribution: 68%, 95%, and 99.7%, respectively. The normal model is bell-shaped, unimodal, and symmetrical about the mean.
Correlation Coefficient
The correlation coefficient (r) measures the strength and direction of a linear relationship between two variables. It is sensitive to outliers and ranges from -1 to 1. Note: Association does not imply causation due to potential lurking variables.
Linear Regression
The equation of a linear regression line is y = mx + c, where:
- m (slope) = b1 = r * sy / sx (sy and sx are the standard deviations of y and x, respectively).
- c (intercept) = ymean – m * xmean.
An increase of 1 in sx corresponds to an increase of r * sy in the predicted value (y^). The intercept (c) is the predicted value when x = 0.
Residuals: The difference between the observed y value and the predicted y value (y – y^). The best-fit line minimizes the sum of squared residuals. The residual plot should show no pattern for an appropriate model. An outlier may not significantly influence the data and could be near the line of best fit.
Extrapolation: Predicting a y value outside the range of x values.
Sampling Methods
Simple Random Sampling (SRS): Each individual in the population has an equal chance of being selected.
Stratified Sampling: The population is divided into strata (subgroups with a common characteristic), and an SRS is taken from each stratum. This method reduces variability and provides more reliable results. Proportional allocation ensures the size of each SRS is proportional to the stratum’s size in the population.
Cluster Sampling: Natural groupings (clusters) are identified in the population, and an SRS of clusters is taken. One-stage clustering includes all individuals from selected clusters. Two-stage clustering involves a further SRS of individuals within selected clusters. This method is used for convenience, practicality, and cost savings.
Systematic Sampling: Every kth individual is selected from the sampling frame. Use only if the sampling frame has no hidden order.
Poor Sampling Procedures
Undercoverage: Underrepresenting certain groups.
Convenience Sampling: Selecting easily accessible individuals.
Voluntary Response Bias: Individuals with strong opinions are more likely to respond.
Nonresponse Bias: Non-respondents may differ significantly from respondents.
Response Bias: Survey questions or the interviewer influence responses.
Confounding Variables
Two variables are confounded if their effects on an outcome cannot be separated. A relationship does not necessarily imply causation. Experiments can establish cause-and-effect relationships.
Experimental Design
Experiment: Investigating the effect of a factor (explanatory variable) on a response variable.
Level: A specific value or category of a factor.
Subjects/Experimental Units: Individuals participating in the experiment.
Treatment: A specific combination of factor levels applied to an experimental unit. In single-factor experiments without blocking, treatments are equivalent to factor levels.
Example:
- Factor: Drug type
- Levels: Drug A, Drug B
- If blocking by gender:
- Males given Drug A
- Males given Drug B
- Females given Drug A
- Females given Drug B
Principles of Experimental Design
Randomization: Averages out the effects of uncontrolled variables.
Replication: Applying treatments to multiple subjects and including a control group (receiving existing or no treatment).
Blocking: Grouping subjects by a characteristic (e.g., gender, habitat) to reduce its effect on the response.
Blinding and Placebo
Blinding: Concealing treatment assignments from subjects and/or evaluators to prevent bias.
- Single-blind: Either subjects or evaluators are unaware of treatment assignments.
- Double-blind: Both subjects and evaluators are unaware.
Placebo: A treatment with no active ingredient, used to establish a baseline or control group.
Independent Events
Two events, A and B, are independent if:
- P(B|A) = P(B)
- P(A|B) = P(A)
- P(A and B) = P(A) * P(B)
Discrete Random Variables
A discrete random variable has a countable set of possible values. The probability model lists each value and its probability. The sum of all probabilities must equal 1.
Continuous Random Variables
A continuous random variable has values within an uncountable set, such as an interval. Probability is represented by the area under a density curve. A uniform random variable has equal probability across its range.

Binomial Distribution
Conditions for a binomial distribution (BINS):
- Binary outcomes (success/failure)
- Independent trials
- N fixed number of trials
- Same probability of success (p) for each trial
X ~ Bin(n, p), where n is the number of trials and p is the probability of success. q = 1 – p = probability of failure.
Mean = np (average number of successes over many repetitions of n trials).
SD = 
Normal approximation for the number of successes: ~N(np,
)
Sampling Distribution of Sample Proportions
Mean( ) = p (population mean)
) = p (population mean)
SD = 
Normal Approximation:
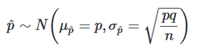
Assumptions/Conditions: Random, independent sample (without replacement). Independence is validated if the sample size is less than 10% of the population. np ≥ 10, nq ≥ 10.
Estimating Population Mean from Sample Mean
~N(mean, SE), where SE = σ / sqrt(n) and μx̄ = μ
Central Limit Theorem (CLT)
If the sample size is sufficiently large (n ≥ 30), the sample mean follows a normal distribution, even if the population distribution is not normal. A larger sample size (n) results in a smaller standard error (SE) and better approximations.
Conditions for CLT: Random, independent sample. np and nq conditions cannot be checked.
Confidence Intervals
CI =
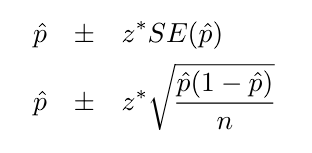
z* is the z-score such that the p-value = (1 – CI) / 2.
Margin of Error (ME) = z* * SE
Assumptions/Conditions: Random, independent sample, np ≥ 10, nq ≥ 10. The confidence interval represents the percentage of intervals that are expected to contain the true population parameter (p^).
Sample Size Determination
Ceiling of
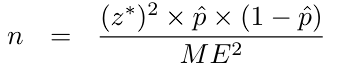
If p^ is unknown, use p^ = 0.5. The confidence level is directly proportional to the width of the interval.
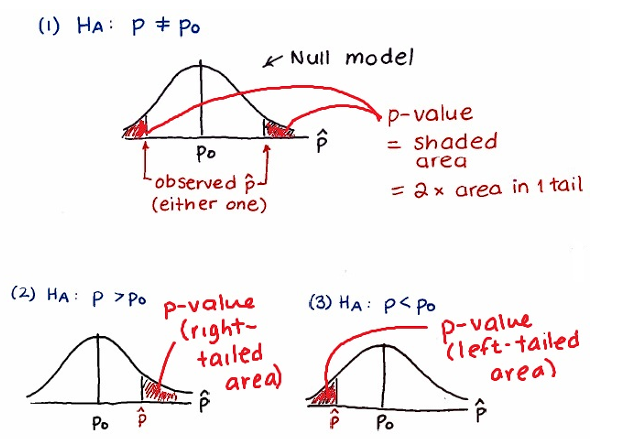
Hypothesis Testing
One-proportion z-test: Verify or assume np ≥ 10, n(1-p) ≥ 10, and the sample is random and independent. Then, the sample is approximately normal.

 (test statistic)
(test statistic)
p-value = pnorm(zo), adjusted for one-tailed or two-tailed tests.
If the p-value is less than the significance level (α), reject H0. Otherwise, fail to reject H0.
Type I error: Rejecting H0 when H0 is true. P(Type I error) = α.
Type II error: Failing to reject H0 when H0 is false. Increasing the sample size (n) decreases the probability of a Type II error.
Confidence Interval for Population Means from Samples
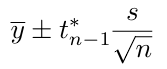
One-sample t-interval. Degrees of freedom (df) = n – 1. Use the qt function in R to find the t-value from p, and the pt function to find the p-value from t. (Use the t-model when the population standard deviation is unknown).
Assumptions/Conditions:
- Random and unbiased sample.
- Independent sampled values (sample size is a small fraction of the population size).
- Nearly normal condition: If the underlying distribution is normal or nearly normal (unimodal and symmetric), the t-model is justified even with a small sample size. For non-normal or unknown distributions, a large sample is needed for the t-model to work well.
Two-Sided Significance Tests and Confidence Intervals
If HA is of the form ≠, reject H0 if the 100(1-α)% confidence interval for the population mean (μ) does not contain μ0. If μ0 falls within the confidence interval, do not reject H0.
Hypothesis Testing for Population Mean

Independent Group Means
If two samples are independent (with sufficiently large sample sizes n1 and n2 if the distributions of y1 and y2 are unknown), the sampling distribution of y1 – y2 will follow the normal model. The null hypothesis states no difference between the averages of the two groups.
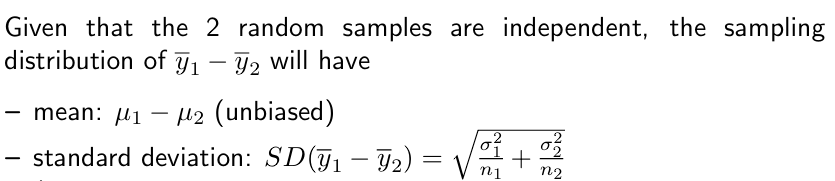
If the standard deviations for both groups are known, construct the confidence interval using mean ± z* * SD.
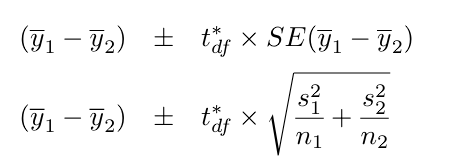
df = min(n1 – 1, n2 – 1), where n1 and n2 are the sample sizes.
This is a two-sample t-interval.
Assumptions/Conditions:
- Two samples are randomly drawn from their respective populations.
- Sampled individuals within the same sample are independent (sample sizes are no more than 10% of their respective population sizes).
- If both y1 and y2 follow the normal model, there are no restrictions on sample sizes. If y1 and y2 are non-normal or have unknown distributions, reasonably large sample sizes are needed to validate the normal approximation and the use of the t-model.
- The two samples must be independent of each other.

Paired Groups
If there is a singular sample size, remember to split it for the k groups.

This is a one-sample t-interval.
Assumptions and Conditions:
- The n pairs are randomly drawn from the population.
- The n pairs are independent of each other.
- If di‘s follow the normal model, there is no restriction on the sample size n.
- If di‘s follow a nearly normal distribution (symmetric and unimodal), a small sample size n is acceptable.
- If di‘s follow an unknown or non-normal distribution, a reasonably large sample size n is needed to validate the normal approximation and the use of the t-model.
- To use the t-model, the population standard deviation must be unknown, and the data must be paired.


Two samples are dependent or paired when individuals in one sample determine the individuals in the second sample. For example, the same printer being used to test different technologies.
Testing for Independence
The null hypothesis states that two variables are not associated. The alternative hypothesis states that they are associated. The row variable has r categories, and the column variable has c categories. The total number of counts is n. Assume the null hypothesis is true when constructing the test statistic.
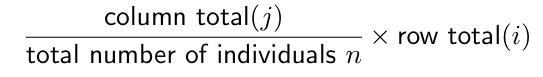
This is for predicting a value (expected value) from means.
Chi-Square Test
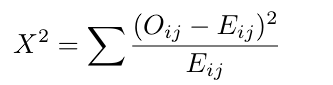
Under the null hypothesis:
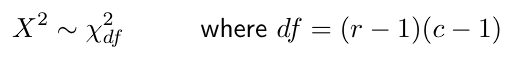
The p-value is the area to the right of the test statistic X2 under the χ2(r-1)(c-1) density curve. Use the pchisq function in R. Condition for the chi-square approximation: Each expected count in the
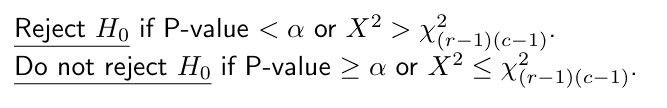
contingency table must be at least 5. To generalize results to the population, the sample must be random and independent.
If H0 is rejected, there is sufficient evidence to conclude that the variables are associated.
ANOVA
ANOVA is used to compare the means of three or more independent populations. It compares the difference between group centers and the spread within individual groups.
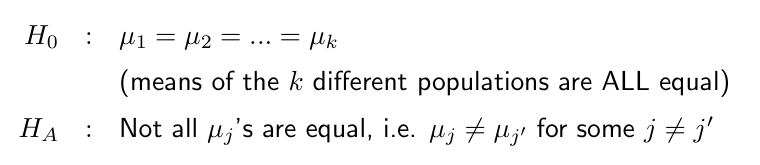
ANOVA F-test: Always use lower.tail = FALSE for ANOVA.
Assumptions for ANOVA:
- The k samples drawn from the k populations must be independent.
- Within each sample j, the individual observations yij‘s are randomly chosen from population j (yij‘s are independent).
- Within each population j, yij‘s follow the normal distribution with mean μj and standard deviation σ. The k populations have a common standard deviation σ.
Sources of Variation in Data
The total variation in the data (SSTotal, total sum of squares) comes from:
- Variation between groups/treatments (SST, treatment sum of squares).
- Variation within groups/treatments (SSE, error sum of squares).
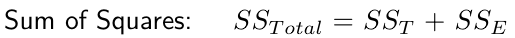
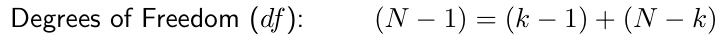
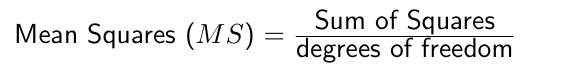
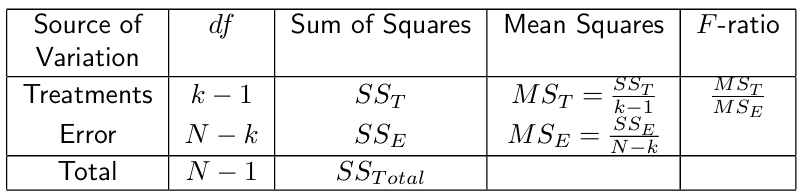


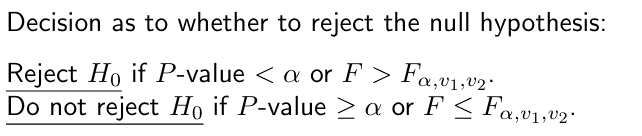
Residual SD:
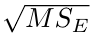
pf gives the p-value for df1 and df2. qt gives the F-ratio from a given p-value for df1 and df2. Use both of these with lower.tail = FALSE.
When H0 is rejected, at least one pair of population means are significantly different.
If the ANOVA F-test is significant at the 10% level, the calculated F-statistic exceeds the critical value at (0.1, df1, df2).
R Formulas and Points
rm(list = ls()) should be at the top of every script.
pbinom(n, size, p) gives P(X ≤ n), whereas pbinom(n, size, p, lower.tail = FALSE) gives P(X > n) (not inclusive of n).
P(X ≥ k) = 1 – P(X ≤ k-1) (at least k)
P(X < k) = P(X ≤ k-1) (less than k)
data = matrix(c(5, 10, 8, 18, 46, 64, 39, 76), nrow = 2, ncol = 4, byrow = TRUE)
chisq.test(data, correct = FALSE)
pnorm gives the p-value from z; qnorm gives the z-value from the p-value.
pt gives the p-value for t(n-1); qt gives the t-value for a given p and df.
Variable Types and Visualizations
Nominal or Ordinal (ranked: mild, moderate, severe): Use bar charts, pie charts, frequency tables, or scatterplots.
Quantitative Variable (measured, usually numeric, e.g., height): Use histograms (use the same scale for multiple histograms).
Contingency Tables: Show the relationship between two categorical variables.
Marginal Distribution: The distribution of one variable while collapsing the other.
Simpson’s Paradox: A change in the direction of association between two categorical variables when considering a third variable.
Skewed to the Right: The right tail is longer (tall on the left side, then decreases on the right). The decreasing area contains unusually large or small outliers (extreme values).


