Statistical Methods for Data Reduction and Classification
Linear Regression
Linear Regression: Finds the best line that summarizes the relationship between two variables. (Imagine a bunch of dots and a line representing the relationship).
Dimensionality Reduction
A large number of variables results in a dispersion matrix that is too large to study. Dimensionality reduction reduces the number of variables to a few. Why?
- Simpler Analysis: Fewer features make it easier to find patterns.
- Faster Processing (e.g., Trading).
- Better Visualization: It’s easier to visualize 2 features than 100.
Correlation Analysis
Correlation analysis tells the strength and direction of the relationship between two variables (-1 to 1). If x increases and y increases, then r is positive. If r is closer to 1, x and y are positively correlated. If r is closer to -1, x and y are negatively correlated. If r is closer to 0, there is a weak relationship between x and y.
How Can Correlation Help Reduce Dimensionality?
Imagine you have many features (X1, X2, …, Xn), and you want to reduce them to a smaller set while keeping the important ones. Here are the steps to reduce features using correlation:
- Find Correlation Between Features: Compare each feature pair (e.g., X1 & X2, X1 & X3) to check if they are highly correlated.
- Compare Correlation With Target Variable (Y): If two features are correlated, check which one has a stronger relationship with Y. Keep the one with a stronger correlation and remove the weaker one.
Probable Error (PEr)
- A limitation of correlation is that it doesn’t consider data size.
- A correlation of 0.5 in 20 samples is weaker than 0.5 in 10,000 samples.
- Probable Error (PEr) helps adjust correlation strength based on sample size.
- Formula: PEr = 0.674 × (1 – r2) / √n
- where r = correlation coefficient and n = number of data points. If:
- r > 6 × PEr → Strong correlation
- r < 6 x PEr
- Example: If you have a large dataset, even a small correlation (e.g., 0.1) could be meaningful!
- Analyze the “correlation.” Why is a correlation of 0.5 with 20 samples *less* significant than a correlation of 0.5 with 10000 samples?
Principal Component Analysis (PCA) – Important
- PCA is a technique used to reduce the number of variables (dimensions) in a dataset while keeping the most important information.
- Why Do We Need PCA?
- Too many variables (features) can make analysis complex and slow.
- Some features are redundant (they contain similar information).
- PCA helps find a smaller set of “important” variables that still explain most of the data.
- How PCA Works
- Collect Data: Imagine you have a dataset with multiple variables (e.g., height, weight, age, income).
- Create a Covariance Matrix: This matrix shows how variables are related to each other.
- Find Eigenvalues & Eigenvectors:
- Eigenvalues tell us how much information (variance) each new feature (Principal Component) captures.
- Eigenvectors represent the directions of the new features.
- Choose Principal Components:
- We keep only the most important components (those with the largest eigenvalues).
- These new features are combinations of original variables but capture most of the important patterns in the data.
- How PCA Works – Covariance Matrix
- A covariance matrix is a table that shows how different variables in your dataset are related to each other. Example:
- Imagine you have a dataset with Height and Weight of people.
- If taller people tend to be heavier, then Height and Weight have a positive covariance (they increase together).
- If one variable goes up while the other goes down, the covariance is negative.
- If they are completely unrelated, covariance is close to zero.
- Imagine you have a dataset with Height and Weight of people.
- A covariance matrix stores these relationships for all variables in a dataset.
- Covariance Matrix = [ Cov(Height, Height) Cov(Height, Weight) Cov(Weight, Height) Cov(Weight, Weight)]
- A covariance matrix is a table that shows how different variables in your dataset are related to each other. Example:
- This helps PCA understand which variables contain similar information so that it can merge them into fewer variables.
- How PCA Works: YES ON THE TEST. PLEASE FILL THIS SECTION OUT
- Eigenvector with covariance matrix
- (Know the difference between the two)
- Eigenvalues with covariance matrix
- Within a three-dimensional graph for both (3-2-2)
- Principal Components
- Worried how to study this beyond barebones definitions
- Pick dimension for new dataset
- Eigenvector with covariance matrix
- How PCA works – YES ON THE TEST
- Mutual Information – NOT ON THE TEST (don’t worry about this one)
Week 3
Naive Bayes Classifier
- The Naive Bayes classifier is a probabilistic machine learning model used for classification tasks.
- It is based on Bayes’ Theorem and assumes that the features (predictors) are conditionally independent given the class label.
- This “naive” assumption simplifies the computation, making the algorithm fast and efficient, even for large datasets.
Multinomial Naive Bayes
- Used for discrete data, such as word counts in text classification.
- Assumes features represent the frequency of events (e.g., word occurrences).
- Example: Spam detection, document classification.
Go through the example of Naive Bayes classifier and connect it to the definition. UNDERSTAND IT (YES)
Example of Multinomial Naive Bayes Classifier
- Imagine you want to classify emails you receive as spam or not spam.
- We take all the words in a normal (not scam) email and create a plot (e.g., a histogram) to see how many times each word occurs in the normal email.
- We can use the histogram (word count) to calculate the probabilities of seeing each word, given that it was a normal email.
- For example, the probability of a word “free” in a normal message = P(free|normal) = the total number of times “free” occurred in normal email (say 5) / the total number of words in a normal email (say 100).
- P(free|normal) = 5/100 = 0.05
- Similarly, the probability of a word “offer” in a normal message = P(offer|normal) = the total number of times “offer” occurred in normal email (say 8) / the total number of words in a normal email (say 100).
- P(offer|normal) = 8/100 = 0.08
- For example, the probability of a word “free” in a normal message = P(free|normal) = the total number of times “free” occurred in normal email (say 5) / the total number of words in a normal email (say 100).
- Now we make a histogram of all the words that occur in a spam email (to count occurrences of each word).
- We can use the histogram (word count) to calculate the probabilities of seeing each word, given that it was a spam email.
- For example, the probability of a word “free” in a spam message = P(free|spam) = the total number of times “free” occurred in spam email (say 20) / the total number of words in a spam email (say 50).
- P(free|spam) = 20/50 = 0.4
- Similarly, the probability of a word “offer” in a spam message = P(offer|spam) = the total number of times “offer” occurred in spam email (say 40) / the total number of words in a spam email (say 50).
- P(offer|spam) = 40/50 = 0.8
- For example, the probability of a word “free” in a spam message = P(free|spam) = the total number of times “free” occurred in spam email (say 20) / the total number of words in a spam email (say 50).
- Now, imagine you got a new email that said “offer!”, and we want to decide if this is a normal email or spam.
- We start with an initial guess about the probability that any email, regardless of what it says, is a normal email.
- We would estimate this guess from the training data.
- For example, since 100 of the 150 emails are normal, P(N) = 100/(100+50) = 0.66
- This initial guess that we observe a normal email is called “prior probability.”
- Now we multiply that initial guess by the probability that the word “offer” occurs in a normal email.
- P(N) × P(offer|normal) = 0.66 × 0.08 = 0.0528
- We can think of 0.0528 as the score that “offer” gets if it belongs to the normal email class.
- Just like before, we start with an initial guess about the probability that any email, regardless of what it says, is spam.
- We would estimate this guess from the training data.
- For example, since 50 of the 150 emails are spam, P(S) = 50/(100+50) = 0.33
- Now we multiply that initial guess by the probability that the word “offer” occurs in a spam email.
- P(S) × P(offer|spam) = 0.33 × 0.8 = 0.264
- We can think of 0.264 as the score that “offer” gets if it belongs to the spam class.
- Because the score we got for “offer” if it belongs to spam is greater than the score if it belongs to the normal email, we will decide that “offer!” is a spam email. (0.264 > 0.0528)
- Understand why it goes either to the spam folder or regular folder.

Naive Bayes “Naive” – YES
- Treats all word orders the same.
- For example, the normal email score for “free offer” is the exact same for “offer free.”
- P(N) × P(free|normal) × P(offer|normal) = P(N) × P(offer|normal) × P(free|normal)
- Treating all word orders the same is different from the real-world use of language.
- Naive Bayes ignores all types of grammar and language rules.
- By ignoring the relationship between words, Naive Bayes has high bias, but because it works well in practice, it has low variance.
- For example, the normal email score for “free offer” is the exact same for “offer free.”
Week 4
K-Means Clustering – YES
- A partitioning method that divides data into k distinct clusters based on distance to the centroid of a cluster.
- Requires the number of clusters (k) to be specified in advance.
- Iteratively assigns data points to clusters and updates cluster centroids.
K-Means Clustering Process – YES
- Initialization: Choose k initial centroids (randomly or using heuristics).
- Assignment Step: Assign each data point to the nearest centroid.
- Update Step: Calculate the new centroids as the mean of all data points assigned to each cluster.
- Repeat: Continue the assignment and update steps until convergence (no change in centroids).
- Imagine a graph with three clusters of points (bottom left, bottom middle, top right, each has a centroid in the center of the clusters of points).
Hierarchical Clustering
- A method of grouping data points into clusters in a step-by-step manner.
- It is like creating a family tree of clusters, where similar data points get grouped together as you move up or down the tree.
Key difference between K-means and hierarchical clustering
Agglomerative (Bottom-Up Approach) Hierarchical Clustering
- Starts with each data point as its own cluster.
- Merges the two most similar clusters at each step.
- Stops when all points form a single large cluster.
- Steps:
- Start: Each data point is treated as an individual cluster.
- Find the Closest Clusters: Measure the similarity (distance) between all clusters.
- Merge: Combine the two closest clusters into one.
- Repeat: Keep merging until only one cluster remains or until a set number of clusters is reached.
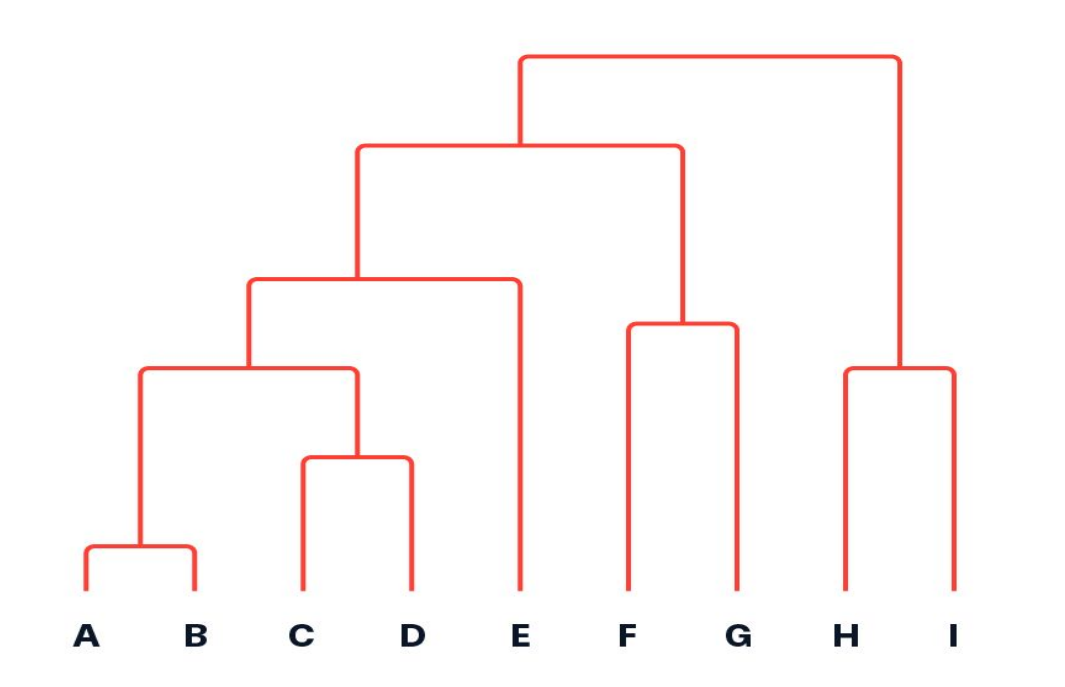
How do you study the clusters in terms of graphs?
Understand the A B C D E graph in the screenshot that’s also in the slides
Methods, Distance Calculation – NOPE
DBSCAN Explanation
- DBSCAN (Density-Based Spatial Clustering of Applications with Noise) is a clustering algorithm that groups together points that are close to each other in dense regions while identifying outliers (noise).
- No need to specify the number of clusters (unlike K-Means).
- Can find clusters of different shapes (not just circular clusters like K-Means).
- Detects outliers (points that don’t fit into any cluster).
- Core Points: Have at least min_samples points within eps distance.
- Boundary Points: Not core points but close to at least one core point.
- Noise Points: Not close enough to any cluster (assigned label -1).
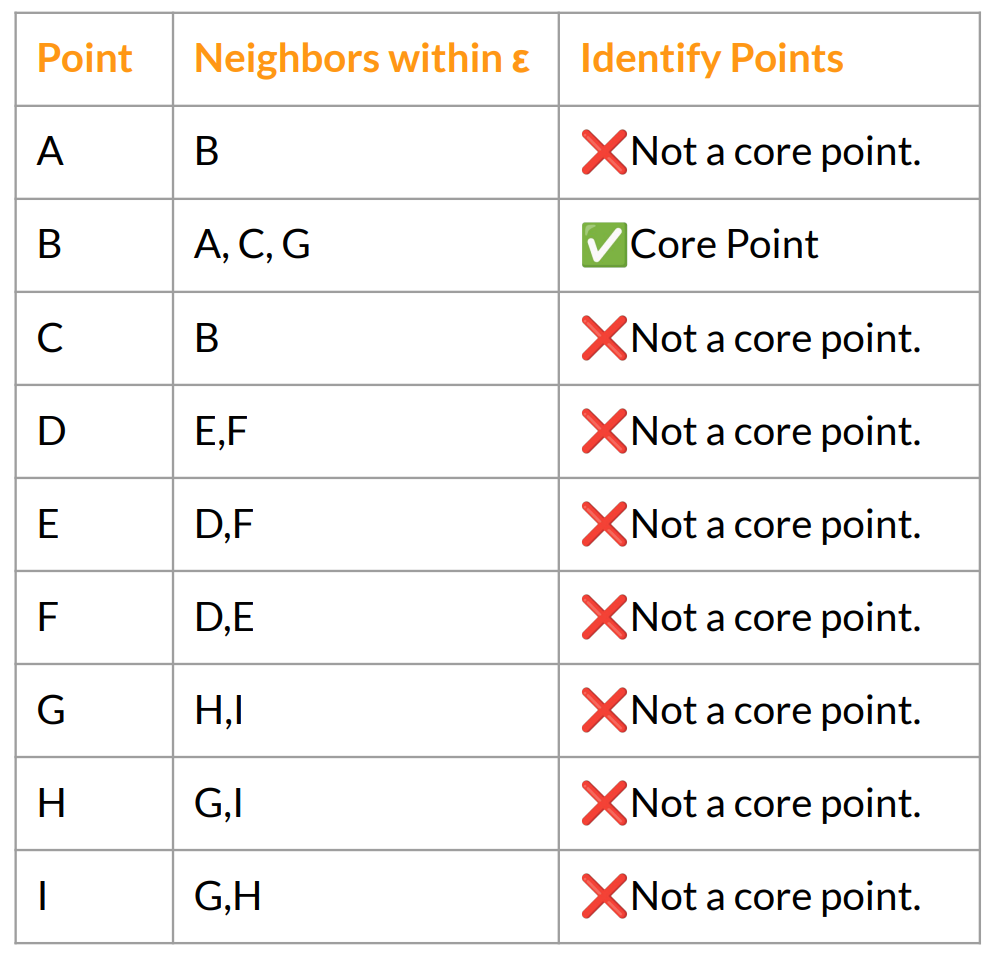
DBSCAN example – YES – understand core points to see if you can cluster points together
- Given Dataset: We have the following points: A, B, C, D, E, F, G, H, I. Let’s assume the following neighborhood relationships exist within distance eps (ε):
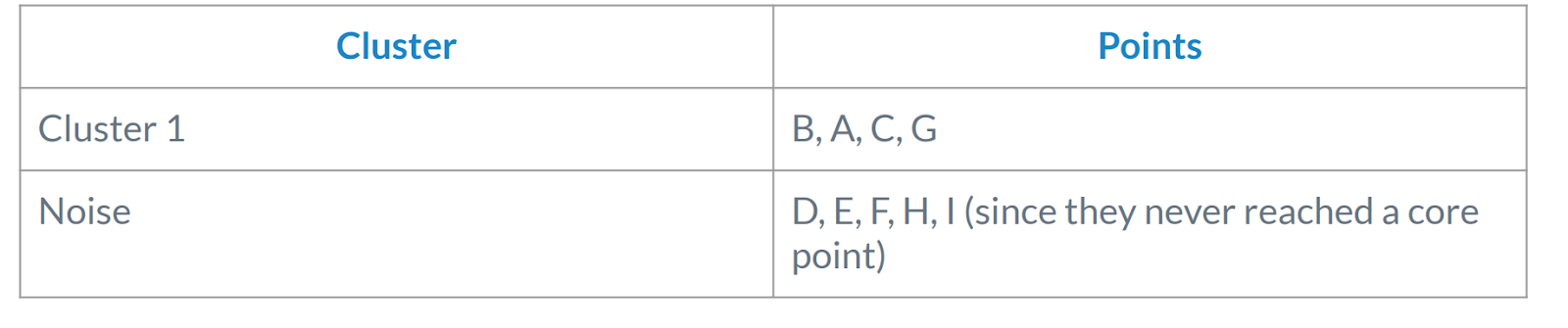
- Step 2: Start a Cluster from Core Points B is a core point, so it forms a new cluster (Cluster 1). B’s directly reachable points (A, C, G) are added to the cluster. Current Cluster 1: {B, A, C, G}
- Step 3: Expand the Cluster
- We check if any of the new members (A, C, G) are also core points.
- C and A are not core points (not enough neighbors), so we don’t expand from them.
- G has only 2 neighbors (H, I), which is less than 3, so it is NOT a core point either.
- Since there are no more core points, the expansion stops here.
- Step 4: Identify Remaining Points
- D, E, and F are not connected to B’s cluster and form another group where all are neighbors of each other.
- None of them are core points (each has only 2 neighbors), so they don’t expand.
- They remain unclustered or noise, depending on the dataset structure.